

Multiple Awk Commands – Introduction
Awk Command is a powerful programming language and command-line tool primarily used for text processing and data manipulation. It provides a rich set of features for extracting and manipulating data from files, especially structured data like columns or fields.
A powerful tool is Awk. Considering that it is a Turing-complete language, any form of program may be created using it. The traditional sorting methods as well as more complicated things like a parser or a translator might be implemented. The authors of Awk’s “AWK Programming Language” book have examples of this kind. But the reason awk is still widely used today has less to do with its universality and more to do with its utility when used in command-line applications.
What does multiple Awk Commands Allow us to do?
AWK Operations:
- Line-by-line scanning of a file
- Field separation for each input line
- Pattern comparison
- Action(s) on matching lines
Suitable For:
- Change the data files
- The creation of formatted reports
Constructions in programming:
- Output lines in a format
- Operations with strings and arithmetic
- Loops and conditions
The basic syntax of an awk command follows the pattern:
awk ‘pattern { action }’ input_file
Let’s break down the components:
awk: The command itself, used to invoke the awk interpreter.
Pattern: The pattern specifies a condition that is matched against each line of input. If the pattern is empty, it matches all lines. Patterns can be simple or complex, using regular expressions.
Action: The action block contains one or more statements that are executed for lines that match the pattern. If the action block is empty, the default action is to print the entire line.
input_file: The input file(s) to be processed by awk. If no input file is specified, awk reads from the standard input.
Awk scripts to read
Use braces around by only citation marks to define an awk script.
$ awk ‘{print “Welcome to awk command tutorial “}’

The same welcome phrase is returned if you type anything.
Ctrl+D can be used to end the program. It seems difficult but be calm—the best is yet to come.
Utilizing Variables
Text files may be processed with awk. For every data field discovered, Awk assigns certain variables:
$0 For the entire line
$1 within the first field
$2 regarding the second field
$n for field number n
In awk, fields are often separated by a whitespace character like a space or tab.
Check out the following example to see how awk handles it:
$ awk ‘{print $1}’ myfile
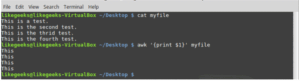
In the aforementioned example, each line’s initial word is printed.
In some files, the separator may occasionally be something other than a space or tab. By using the -F option, you may specify it:
$ awk -F: ‘{print $1}’ /etc/passwd
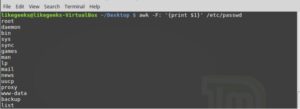
The passwd file’s first field is printed by this command. We also do because the passwd file uses a colon as a separator.
Examples of multiple Awk commands
Here are a few examples of awk commands with explanations:
- Print specific fields from a CSV file:
Let’s say you have a CSV file with comma-separated values and you want to extract only the first and third fields. You can use the following awk command:
awk -F ‘,’ ‘{ print $1, $3 }’ input.csv
-F ‘,’ sets the field separator as a comma. $1 and $3 refer to the first and third fields, respectively.
- Print lines longer than a specific length:
Suppose you have a text file and you want to print only the lines that are longer than 50 characters. You can use the following command:
awk ‘length > 50’ input.txt
Here, length is a built-in function that returns the length of the current line. If the length is greater than 50, the line is printed.
- Sum values in a specific column:
If you have a file with numeric values in a particular column, you can calculate the sum of those values using awk. Assuming the values are in the second column, you can use the following command:
awk ‘{ sum += $2 } END { print sum }’ input.txt
sum += $2 accumulates the values from the second column into the variable sum. The END block is executed after all lines are processed and print the final sum.
- Extract lines based on a pattern:
If you want to extract lines containing a specific pattern, you can use regular expressions in awk. For example, let’s extract lines that start with the word “Error”:
awk ‘/^Error/ { print }’ input.txt
^Error represents a pattern that matches lines starting with “Error”. If a line matches, it is printed.
- Replace text in a file:
Awk can be used to perform text replacement within a file. Suppose you want to replace all occurrences of “old” with “new” in a file. You can use the following command:
awk ‘{ gsub(“old”, “new”); print }’ input.txt
gsub is an awk function that globally substitutes “old” with “new” in each line. The modified line is then printed.
- Calculate the average of values in a column:
Let’s say you have a file with numeric values in the second column, and you want to calculate the average of those values. You can use the following command:
awk ‘{ sum += $2 } END { print “Average:”, sum/NR }’ input.txt
sum += $2 accumulates the values from the second column into the variable sum. NR represents the total number of records (lines) processed. In the END block, the average is calculated by dividing the sum by the total number of records.
- Print lines within a specific range:
If you want to extract lines within a specific line number range, you can use the following command:
awk ‘NR >= 5 && NR <= 10 { print }’ input.txt
NR represents the current line number. In this example, lines 5 to 10 (inclusive) will be printed.
- Perform calculations on specific columns:
multiple Awk Commands allows you to perform arithmetic calculations on specific columns. Let’s say you have a file with three columns representing quantity, price, and total. You want to calculate the total cost by multiplying the quantity and price columns. You can use the following command:
awk ‘{ total = $1 * $2; print “Total:”, total }’ input.txt
Here, $1 represents the first column (quantity) and $2 represents the second column (price). The product of the two columns is stored in the variable total and printed.
- Print unique values from a column:
If you have a file with a column containing duplicate values, and you want to extract only the unique values from that column, you can use the following command:
awk ‘!seen[$1]++’ input.txt
This command uses an associative array seen to keep track of the values in the first column. It is printed if a value has not been seen before (!seen[$1] evaluates to true). The ++ increments the count of the seen value.
- Calculate and print the maximum value from a column:
If you want to find and print the maximum value from a specific column, you can use the following command:
awk ‘max < $2 { max = $2 } END { print “Max value:”, max }’ input.txt
This command compares the value in the second column ($2) with the current maximum value (max). If the value is greater, it becomes the new maximum. After processing all lines, the final maximum value is printed.
- Count occurrences of a specific pattern
If you want to count the number of occurrences of a specific pattern in a file, you can use the following command:
awk ‘/pattern/ { count++ } END { print “Count:”, count }’ input.txt
This command uses a pattern to match lines that contain the desired pattern. For each matching line, the count variable is incremented. In the END block, the final count is printed.
- Print lines between two patterns:
If you want to extract and print lines between two specific patterns, you can use the following command:
awk ‘/start_pattern/, /end_pattern/’ input.txt
This command matches lines starting from the line that matches start_pattern and continuing until a line matches end_pattern. All lines between the two patterns (inclusive) are printed.
- Calculate column-wise sum:
Suppose you have a file with multiple columns, and you want to calculate the sum of each column. You can use the following command:
awk ‘{ for (i=1; i<=NF; i++) sum[i] += $i } END { for (i=1; i<=NF; i++) print “Column”, i, “Sum:”, sum[i] }’ input.txt
This command uses a loop to iterate through each field (column) represented by NF. The sum of each column is accumulated in the array sum. In the END block, it prints the sum for each column.
- Select lines based on multiple conditions:
If you want to filter lines based on multiple conditions, you can combine them using logical operators. For example, let’s select lines where the value in the second column is greater than 10 and the value in the third column is less than 5:
awk ‘$2 > 10 && $3 < 5 { print }’ input.txt
This command uses the logical operators && to combine the conditions. Only the lines that satisfy both conditions are printed.
- Manipulate the output format:
Awk provides control over the output format using the printf function. Suppose you want to print the first column left-aligned and the second column right-aligned with a specific width:
awk ‘{ printf “%-10s %5d\n”, $1, $2 }’ input.txt
This command uses printf to format the output. %10s specifies a left-aligned string with a width of 10, and %5d specifies a right-aligned integer with a width of 5. The corresponding values from the first and second columns are printed using these formats.
Wrapping Up
multiple Awk Commands can truly help you accomplish your goals, whether you’re attempting to extract and prepare some textual data or create a useful command to simplify your life. There are around 520 instances of “awk” throughout our code base.
Using the Awk tool, a programmer may create short but powerful programs by writing statements that specify text patterns to be looked for in every line of the file and the action to be taken when a match is found. Multiple Awk Commands are normally used for processing and scanning patterns. It checks one or more files to determine whether any lines match the specified patterns, and if so, it takes the necessary action.
You can learn about linux more deeply by clicking the link below
https://linuxiron.com/what-is-linux-a-whole-introduction/
Learn about the other linux commands by clicking the links below
https://linuxiron.com/echo-command-in-linux/
https://linuxiron.com/how-to-use-nice-renice-commands-in-linux/
https://linuxiron.com/how-to-use-kill-commands-in-linux/
https://linuxiron.com/a-beginners-guide-to-htop-for-process-management/
https://linuxiron.com/15-useful-yum-commands-in-linux/
https://linuxiron.com/how-to-use-the-top-command-in-linux/
https://linuxiron.com/17-ps-command-to-monitor-linux-process-with-examples-linuxiron/
https://linuxiron.com/12-cat-commands-in-linux-with-examples/